- RNN
用来连接先前的信息到当前的任务上,我们仅仅需要知道先前的信息来执行当前的任务。当相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
但,当前相关信息和当前预测位置之间的间隔就肯定变得相当的大。不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
缺点:RNN sequence-to-sequence models have not been able to attain state-of-the-art results in small-data regimes。 (Google 《attention is all you need》提出)
- LSTM
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
但,LSTM的重复网络模块的结构很复杂,它实现了三个门计算,即遗忘门、输入门和输出门。
- GRU(Gated Recurrent Unit)
GRU则是LSTM的一个变体,保持了LSTM的效果,同时结构更加简单,所以它也非常流行。
GRU模型只有两个门了,分别为更新门和重置门。更新门 用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门 用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
GRU参数更少因此更容易收敛,但是数据集很大的情况下,LSTM表达性能更好。
GRU缺点:the output of GRU is always averaged to get utter level embeddings, ignoring one’s speaking style。(An End-to-End Text-Independent Speaker Identification System on Short Utterances(interspeech 2018)提出)
解决办法:只将GRU的最后一个输出连接到affine以获得单个话语级特征,并进一步使用ResCNN来学习判别式说话人嵌入。以这种方式,不仅捕获了顺序性质,而且在嵌入中很好地建模了光谱相关性。
- 3D-Conv(C3D
可以同时对外观和运动信息建模。
,在有限的探究框架中,所有层使用3×3×3卷积核效果最好。
15年ICCV的论文《Learning Spatiotemporal Feature with 3D Convolutional Networks》设计一种网络,把通过简单的线性分类器学到的特征称为为C3D(Convolutional 3D),提出的C3D卷积网络是3D卷积网络的里程碑。
C3D[2]是Facebook的一个工作,它主要是把2D Convolution扩展到3D。其原理如下图,我们知道2D的卷积操作是将卷积核在输入图像或特征图(feature map)上进行滑窗,得到下一层的特征图。例如,图(a)是在一个单通道的图像上做卷积,图(b)是在一个多通道的图像上做卷积(这里的多通道图像可以指同一张图片的3个颜色通道,也指多张堆叠在一起的帧,即一小段视频),最终的输出都是一张二维的特征图,也就是说,多通道的信息被完全压缩了。而在3D卷积中,为了保留时序的信息,对卷积核进行了调整,增加了一维时域深度。如图(c)所示,3D卷积的输出仍是一个三维的特征图。因此通过3D卷积,C3D可以直接处理视频,同时利用表观特征和时序特征。
该网络图如下:

网络图描述:该网络具有8个卷积层、5个池化层、两个全连接层,以及一个softmax输出层。所有3D卷积滤波器均为3×3×3,步长为1×1×1。为了保持早期的时间信息设置pool1核大小为1×2×2、步长1×2×2,其余所有3D池化层均为2×2×2,步长为2×2×2。每个全连接层有4096个输出单元。
下图,在UCF101数据集上(101个人类动作类别的13,320个视频),与基于循环神经网络(RNN)的方法相比,C3D性能分别优于长期循环卷积网络(LRCN)和LSTM复合模型14.1%和9.4%。C3D特征既紧凑又具有识别力。
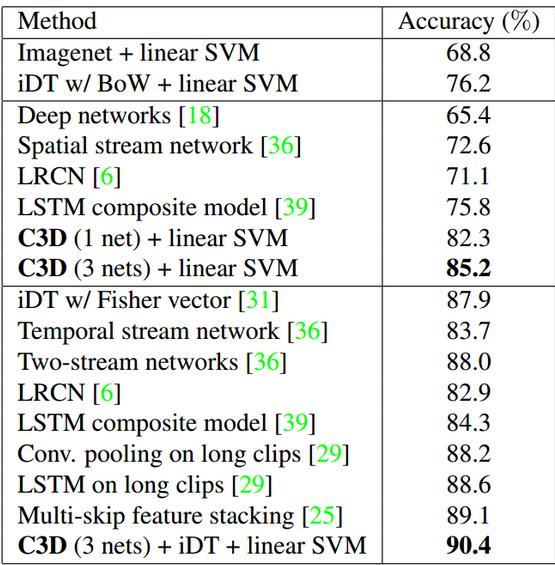
C3D与2015年最先进的方法相比。顶部:线性SVM的简单特征; 中间:仅采用RGB帧作为输入的方法;底部:使用多个特征(如光流、密集轨迹)组合的方法。结果表明c3D结合密集轨迹和SVM分类器效果最好
–附:
基于pytorch的c3d模型代码:https://github.com/MRzzm/action-recognition-models-pytorch
- I3D
I3D[3] 是 DeepMind 基于 C3D 作出的改进,值得一提的是 I3D 这篇文章也是发布 Kinetics数据集的文章。其创新点在于模型的权重初始化,如何将预训练好的2D ConvNets的权重赋值给3D ConvNets。具体地,将一张图像在时间维度上重复T次可以看作是一个(非常无聊的)T帧的视频,那么为了使该视频在3D结构上的输出和单帧图像在2D结构的输出相等,可以使3D卷积的权重等于2D卷积的权重重复T次,再将权重缩小T倍以保证输出一致。I3D在Kinetics数据集上进行预训练然后用于UCF101,其精度可达到98.0%。
- P3D
《learning spatio-temporal representation with pseudo-3D residual networks》ICCV2017
P3D[4]是MSRA基于C3D作出的改进,基本结构是把ResNet扩展为“伪”3D卷积,“伪”3D卷积的意思是利用一个1*3*3的2D空间卷积和3*1*1的1D时域卷积来模拟常用的3*3*3的3D卷积,如下图所示。P3D在参数数量、运行速度等方面对C3D作出了优化。
GitHub链接https://github.com/ZhaofanQiu/pseudo-3d-residual-networks
- Transformer
attention is all you need阅读笔记
Google在2017的《Attention is all you need》,提出解决sequence to sequence问题的transformer模型,用全attention的结构代替了lstm。
是第一个完全基于attention的序列转换模型,代替了encoder-decoder结构的递归网络,训练效果比之前的模型好。
RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
1.时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力,训练速度快;
2.顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
创新之处在于提出了两个新的Attention机制,分别叫做 Scaled Dot-Product Attention 和 Multi-Head Attention。
局限/未来发展方向:
- 当前仅用于文本形式的输入输出,还未使用到图像,语音,视频。
- 使生成顺序更少。
Transformer代码已经发布在TensorFlow的tensor2tensor库中。
- Two-Stream Network及其衍生系列(不理解)
Two Stream[5]是VGG组的工作(不是UGG哦),其基本原理是训练两个ConvNets,分别对视频帧图像(spatial)和密集光流(temporal)进行建模,两个网络的结构是一样的,都是2D ConvNets,见下图。两个stream的网络分别对视频的类别进行判断,得到class score,然后进行分数的融合,得到最终的分类结果。
可以看出Two-Stream和C3D是不同的思路,它所用的ConvNets都是2D ConvNets,对时序特征的建模体现在两个分支网络的其中一支上。Two-Stream的实验结果,在UCF101上达到88.0%的准确率。
在spatial stream和temporal stream如何融合的问题上,有很多学者作出了改进。
[6]在two stream network的基础上,利用3D Conv和3D Pooling进行spatial和temporal的融合,有点two stream + C3D的意思。另外,文章将两个分支的网络结构都换成了VGG-16。在UCF101的精度为92.5%。
TSN[7]是CUHK的工作,对进一步提高two stream network的性能进行了详尽的讨论。two stream在这里被用在视频片段(snippets)的分类上。关于two stream的输入数据类型,除去原有的视频帧图像和密集光流这两种输入外,文章发现加入warped optical flow也能对性能有所提高。在分支网络结构上尝试了GoogLeNet,VGG-16及BN-Inception三种网络结构,其中BN-Inception的效果最好。在训练策略上采用了跨模态预训练,正则化,数据增强等方法。在UCF101上达到94.2%的精度。
- TDD(不理解)
TDD[8]是对传统的iDT[9]算法的改进(iDT算法是深度学习以前最好的行为识别算法),它将轨迹特征和two-stream network结合使用,以two-stream network作为特征提取器,同时利用轨迹对特征进行选择,获得轨迹的深度卷积描述符,最后使用线性SVM进行视频分类。TDD是一个比较成功的传统方法与深度学习算法相结合的例子,在UCF上达到90.3%的精度。
ActionVLAD(不理解)
ActionVLAD[10]是一种特征融合的方式,它可以融合two stream的特征,C3D的特征以及其他网络结构的特征。其思想是对原有的特征计算残差并聚类,对不同时刻的帧进行融合,得到新的特征。ActionVLAD是对视频空间维度和时间维度的特征融合,使得特征的表达更全面。Non-local Network(不理解)
Non-local Network[11]是Facebook何恺明和RBG两位大神近期的工作,非局部操作(non-local operations)为解决视频处理中时空域的长距离依赖打开了新的方向。我们知道,卷积结构只能捕捉数据的局部信息,它对于非局部特征的信息传递不够灵活。Non-local Network则根据所有帧所有位置的信息对某个位置进行调整。文章把这个block加在I3D上做了实验,在Charades上精度提升2%
scquence2senquence
encoder-decoder
https://blog.csdn.net/qq_28743951/article/details/78974058
https://blog.csdn.net/wangyangzhizhou/article/details/77332582
https://blog.csdn.net/pipisorry/article/details/84946653
https://www.jianshu.com/p/e416b837351d
https://www.jianshu.com/p/526e90bb2ba0