多篇说话人识别论文总结
将话语映射到说话人身份子空间,其中说话者的相似性可以通过欧几里德距离来测量
注:speaker embedding是指唯一确定的0-1一维向量,属于目标人是1(唯一),向量其余元素是0
注:i-vector是声纹说话人识别中的说话人矢量
i-vector
讲解博客
采用 GRU 来提取时间话语级别的特征,以保留一个人的说话风格。 然后,训练ResCNN模型来对说话人进行鲁棒嵌入。 最后,整个系统(包括GRU和ResCNN)通过使用所提出的损失函数联合优化,称为speaker identity subspace loss
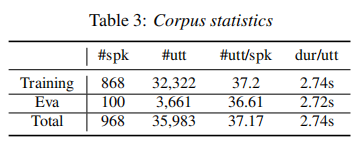
数据输入:968个发言者,35,983句话,约27个小时的中文普通话发音。 每个人有大约37个话语,其持续时间大多在2到5秒左右。 通过随机选择100个说话者作为测试集,其他作为训练集。
GRU提取 utterance-level feature; contains more speaker characteristics
提出GRU缺点: the output of GRU is always averaged to get utter level embeddings, ignoring one’s speaking style。解决办法:只将GRU的最后一个输出连接到affine以获得单个话语级特征,并进一步使用ResCNN来学习判别式说话人嵌入。以这种方式,不仅捕获了顺序性质,而且在嵌入中很好地建模了光谱相关性。
ResCNN 假设一个“不同的话语”可以被视为理想说话者身份子空间中单个对象的变换。基于此假设,利用残差卷积神经网络(ResCNN)架构对变换进行建模
the speaker identity subspace loss significantly improves the discriminative ability of our system
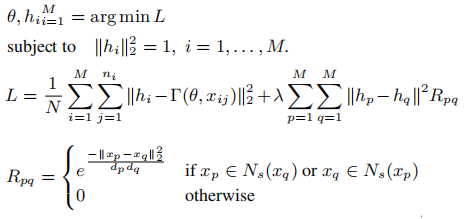
注:hp, hq 是说话者p ,q的身份向量。 Rpq是说话者p,q的声音距离关系
实验结果表明:
该端到端系统性能更好,并且提出的说话者身份子空间丢失使得说话人身份嵌入更具辨别力。
同时,实验对比指出:
- 话语时长5s足以训练短时说话人识别系统。 此外,持续时间较长可能会带来进一步改善,但也带来冗余。
- 每个人说 3-5 句话是比较合适的。
GE2E:具有新损失函数GE2E的模型通过将训练时间减少> 60%,在更短的时间内将EER降低10%以上,从而学习更好的模型
先前工作背景:Tuple-Based End-to-End Loss(TE2E)
TE2E原理(还没做)
- 数据输入
GE2E的训练数据基于一次性的大数据量的语句,一个batch包含N个人,M句话/人。(Xji代表j说话者的第i句话)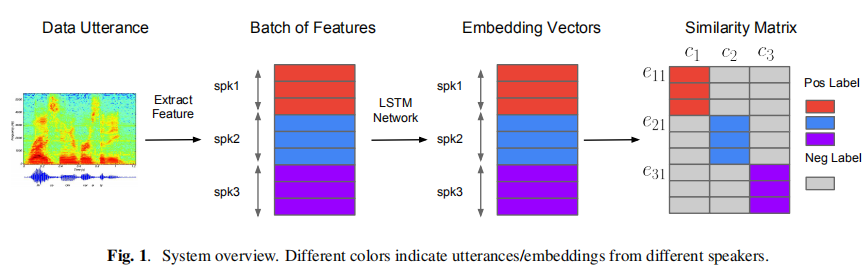
- GE2E的损失函数
features extracted from each utterance xji——>LSTM network——>a linear layer——>output:f(xji,w)
注:w是LSTM和linear layer的参数
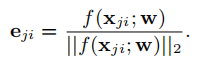
eji(正则化后的vector) represents the embedding vector of the jth speaker’s ith utterance

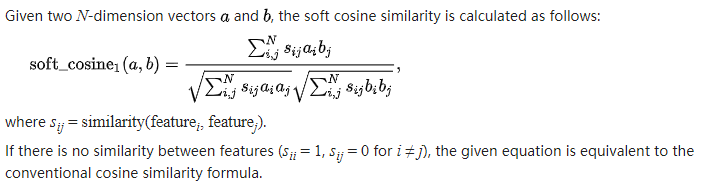
损失函数的两种算法
- softmax

contrast

正项对应于朝向cj(蓝色三角形)推动eji(蓝色圆圈)。 负项对应于拉动eji(蓝色圆圈)远离ck(红色三角形),因为ck与ck0相比更像eji。 因此,对比度损失使我们能够专注于困难的嵌入向量和负质心对。两种损失函数比较:(1)两种函数都有用;(2)contrast损失对于td-sv表现更好,而softmax损失对于ti-sv表现稍好。
注:在计算真实说话者的质心时移除eji使得训练稳定并有助于避免琐碎的解决方案。 因此,在计算负相似性时仍使用公式1(即k != j),但我们在k = j时使用公式8
综上所述:
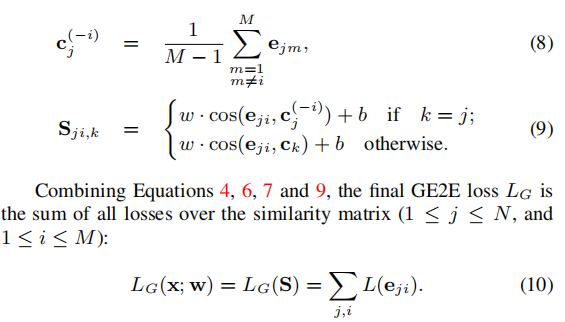
- TE2E、GE2E比较
a single batch in GE2E loss update: have N speakers,
each with M utterances. Each single step update will push all N×M embedding vectors toward their own centroids, and pull them away the other centroids.
all possible tuples in the** TE2E loss function** for each xji.(没看懂)
each update for xji in our GE2E loss is identical to at least 2(N − 1) steps in our TE2E loss,所以,GE2E比TE2E训练次数更少,更有效率。
- Training with MultiReader
利用多个不同的数据源来做。为每个数据源的损失函数设置不同的权重,权重越高该数据源越重要;求所有数据源的损失函数的加权和。
5.1 Text-Dependent Speaker Verification实验
训练数据有两个,(1)是 150M 句话 630K 说话者的“OK Google”
(2)是共 1.2M 句 18K 说话者的 “OK/Hey Google” 。第一个数据库比第二个大很多。
Table1 测试数据: 665 speakers with an average of 4.5 enrollment utterances and 10 evaluation utterances per speaker
Table2 测试数据:83 K different speakers and environmental conditions, from both anonymized logs and manual collections. We use an average of 7.3 enrollment utterances and 5 evaluation utterances per speaker.(the GE2E model took about 60% less training time than TE2E)
测试结果
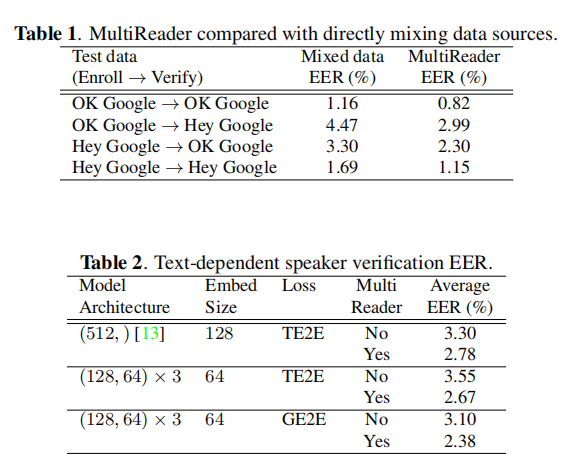
注:The baseline model is a single layer LSTM with 512 nodes and an embedding vector size of 128 [13]. The second and third rows’ model architecture is 3-layer LSTM.
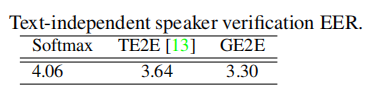
5.2 Text-Independent Speaker Verification实验
数据预处理divide training utterances into smaller segments, which we refer to as partial utterances. 不要求所有partial utterances具有相同的长度,但同一batch中的partial utterances所有必须具有相同的长度为t帧(140<=t<=180).
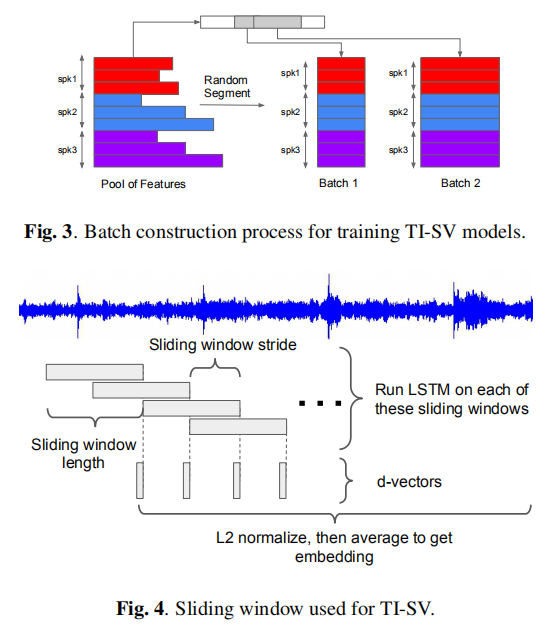
滑动窗口的处理for every utterance we apply a sliding window of fixed size (140 + 180)/2 = 160 frames with 50% overlap.
We compute the d-vector for each window. The final utterance-wise d-vector is generated by L2 normalizing the window-wise d-vectors, then taking the element-wise averge (as shown in Figure 4)
训练数据:36M utterances from 18K speakers
测试数据:1K speakers with in average 6.3 enrollment utterances and 7.2 evaluation utterances per speaker
测试结果
GE2E training was about 3× faster than the other loss functions。
- 论文总结
提出了GE2E损失函数,该函数正确率高,且所需训练时间短。
引入了MultiReader技术来组合不同的数据源,使模型能够支持多个关键字和多种语言。
针对不同长度的utterance提出了切分的想法。