总结多篇 action recognition 的论文
Large-scale Video Classification with Convolutional Neural Networks(CVPR2014)
使用CNN拓变体,用于视频分类;
使用两种不同的分辨率的帧分别作为输入,输入到两个CNN中,在最后的两个全连接层将两个CNN统一起来;两个流分别是低分辨率的内容流和采用每一个帧中间部分的高分辨率流(如图1);
高分辨率流学习灰度,高频特征,而低分辨率流模拟较低的频率和颜色。

- 将从自建数据库学习到的CNN结构迁移到UCF-101数据集上面。
在考虑时间关联性方面,作者提出了四种方案(如图2),并且进行了相关实验,实验的结果表示这四种方面都能取得很好的结果。
Slow Fusion网络效果最好 。
- 作者也做了关于迁移学习的实验,在迁移对为未训练的数据分类时,对最后一层softmax、最后两层softmax、整个网络分别再训练,得到了效果对比:仅训练最后两层softmax效果较好。
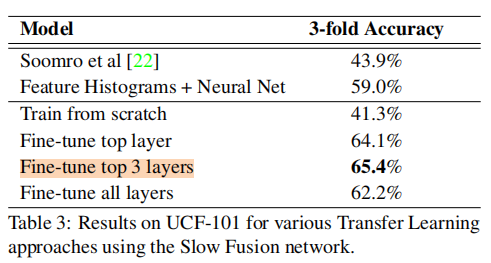
Two-Stream Convolutional Networks for Action Recognition in Videos(NIPS 2014)
阅读时间:2019年5月27日
1.Multi-task learning多任务学习
Multi-tasklearning (多任务学习)是和single-task learning (单任务学习)相对的一种机器学习方法。拿大家经常使用的school data做个简单的对比,school data是用来预测学生成绩的回归问题的数据集,总共有139个中学的15362个学生,其中每一个中学都可以看作是一个预测任务。单任务学习就是忽略任务之间可能存在的关系分别学习139个回归函数进行分数的预测,或者直接将139个学校的所有数据放到一起学习一个回归函数进行预测。而多任务学习则看重任务之间的联系,通过联合学习,同时对139个任务学习不同的回归函数,既考虑到了任务之间的差别,又考虑到任务之间的联系,这也是多任务学习最重要的思想之一。
优势:能发掘这些子任务之间的关系,同时又能区分这些任务之间的差别。比如多标签图像的分类,人脸的识别等等。
方法:大致可以总结为两类,一是不同任务之间共享相同的参数(common parameter),二是挖掘不同任务之间隐藏的共有数据特征(latent feature)。
时间流使用多任务训练时,不论有无空间流,效果都比单任务训练效果好。
2. two-stream 的连接方式
连接时间和空间流的方法:(1)是在两个网络的full6或full7层的顶部训练一组全连接层,但会过度拟合。(2)使用平均或线性SVM融合softmax分数
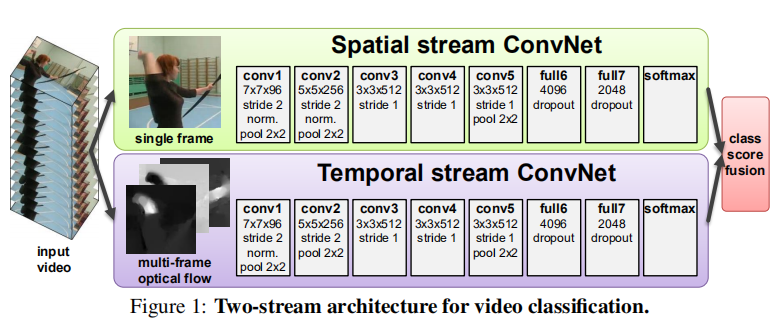
3. 两种时间流堆栈方式
(1)光流堆叠 Optical flow stacking : 计算每两帧之间相同位置的光流,然后简单的stacking
(2)轨迹堆叠 Trajectory stacking : 轨迹叠加就是假设第一帧的某个像素点,我们可以通过光流来追踪它在视频中的轨迹
Learning Spatiotemporal Features with 3D Convolutional Networks##(CVPR 2015)
阅读时间:2019年5月28日
1. 问题
- 2D卷积对时空特征的学习不好
- 本文将二维卷积推广到了三维,提取的特征高效、紧致、使用简单
2. 方法
- 用3D卷积网络,同时提取空间和时间信息
- All 3D convolution kernels are 3 × 3 × 3 with stride 1
- All pooling kernels are 2 × 2 × 2, except for pool1 is 1 × 2 × 2
- 学习到的特征输入到线性分类器(多分类线性SVM),分类效果好
3. 收获
- 3D卷积更加适合学习时域空域(spatiotemporal)特征学习
- 特征紧凑,计算效率高,易于训练和使用

4. C3D学到了什么?
观察到C3D首先关注前几帧中的appearance,并跟踪后续帧中的显着运动。Thus C3D differs from standard 2D ConvNets in that it selectively attends to both motion and appearance.
可以在卷积层后使用反卷积,查看网络学到了什么。
C3D可以很好地捕获外观和运动信息,因此与基于外观的深度特征的Imagenet结合没有任何好处。另一方面,将C3D与iDT结合起来是有益的,因为它们彼此高度互补。实际上,iDT是基于光流跟踪和低级梯度直方图的手工制作功能,而C3D则捕获高级抽象/语义信息。
** # t-SNE:可视化**,能保持局部结构的能力,高维数据空间中距离相近的点投影到低维中仍然相近。use deconvolution to project the top activations of these clips back into image space
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks##( ICCV 2017) P3D
使用的可视化代码DeepDraw
阅读时间:2019年5月29日
0. 为什么提该网络
- 如何更好地提取视频的空间时序特征信息对于视频内容的分析具有重要的意义;
- 2D卷积神经网络不能很好的学习到视频的时序信息,而看起来更加合理的3D卷积神经网络却需要大量的计算量,而且需要在没有预训练参数的情况下从头开始训练;
- 在2D Conv网络结构基础上增加pooling或者RNN的方法不能很好地提取视频的低层信息间的联系。
1. 问题
- 3D Convolutions对视频的时域空域特征学习更好
- 重头训练一个深的3D CNN会消耗大量成本和内存
- 随机初始化的三维卷积核需要大量精细标注的视频数据来进行训练
- 本文提出基于伪三维卷积和残差学习的神经网络模块
- 在CVPR 2017的Activity Net Challenge的Dense-Captioning任务中获得第一名
2. 方法

- the key component in each block is a combination of one 1 × 3 × 3 convolutional layer and one layer of 3 × 1 × 1 convolutions in a parallel or cascaded fashion, that takes the place of a standard 3 × 3 × 3 convolutional layer.
- 即 con3D = S + T = 1 × 3 × 3 + 3 × 1 × 1 如上图上部分所示
- 其中二维卷积核可以使用图像数据进行预训练,对于已标注视频数据的需求也会大大减少
- P3D Blocks :P3D-A,P3D-B,P3D-C 分别使用串行、并行和带捷径(shortcut)的串行三种方式,如上图中间部分所示
- P3D ResNet:三种伪三维残差单元替代ResNet中的二维残差单元,如上图下部分所示
3. 收获
- 以后遇到时域的数据,可以增加一个网络学习
- 要设计非常深的网络时要借鉴残差网络的思想
- 训练非常深的3D CNN非常困难,需要很大的计算量。更重要的是,使用Sports-1M数据集中的帧直接微调ResNet-152可以获得比从头开始训练的C3D更高的准确度
** # TDD特征:Trajectory-pooled Deep-convolutional Descriptor**
结合了hand-craft features 和 deep convolutional features两种提取特征的方式,
** # DeepDraw:P3D ResNet模型使用DeepDraw 来对模型学习的内容 **可视化。https://github.com/auduno/deepdraw
整个过程分两步:
- 利用cnn学习convolutional features
- 采用trajectory-constrained sample and pooling策略对convolutional features进行aggregate,形成descriptor。
- 利用费舍尔矢量将这些局部的TDDs aggregate成一个全局长矢量,再用svm分类。
优点:
- 自动的学习视频特征,避免了过多的hand-craft 提取。
- 考虑到了视频的时间特性,采用trajector-constrained sample and pooling对cnn自动学习到的特征进行aggregate。
- 并且证明了TDD其实就是各类hand-craft的融合。(our results demonstrate that our TDDs are complementary to those hand-crafted features (HOG, HOF, and MBH) and the fusion of them is able to further boost the recognition performance.)
Attentional Pooling for Action Recognition (NIPS 2017)
阅读时间:2019年6月2日
代码 https://github.com/rohitgirdhar/AttentionalPoolingAction
1.问题
- 传统一阶注意力网络大多为学习一个locations*
1的mask向量,向量的值代表了对应位置上的权重,但是它没有挖掘到,location之间的关系或者说是相互作用的权重
2.方法
Attentional pooling as low-rank approximation of second-order pooling
Second-order pooling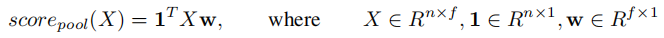
Low-rank second-order pooling
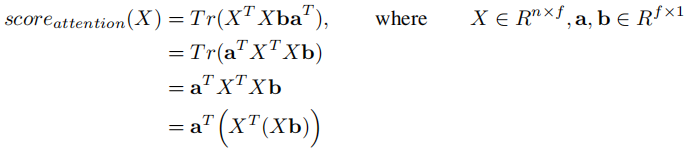
Top-down attention
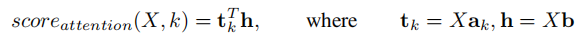
融合 注意力和 低阶二阶池化,引入了一种简单的注意力表达式作为低阶二阶汇集,整合自下而上的显着性和自上而下的注意力。通过 Attention pooling 层可以学到一个二阶 attention 矩阵,而不仅仅只是一个 mask 向量,然后再 conbine 二阶和一阶的 mask ,就能得到更加精确的注意力关注区域
# 目标检测网络 详细讲解
R-CNN、Fast R-CNN、Faster R-CNN
# 空间金字塔池化
将金字塔思想加入到CNN,实现了数据的多尺度输入。一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。
如下图所示,在卷积层和全连接层之间加入了SPP layer。此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
# TSN(Temporal Segment Networks)
基于长范围时间结构,结合了稀疏时间采样策略来保证使用整段视频时学习得有效和高效。基于two-stream方法构建,但不同于two-stream采用单帧或者单堆帧,TSN使用从整个视频中稀疏地采样一系列短片段,每个片段都将给出其本身对于行为类别的初步预测,从这些片段的“共识”来得到视频级的预测结果。
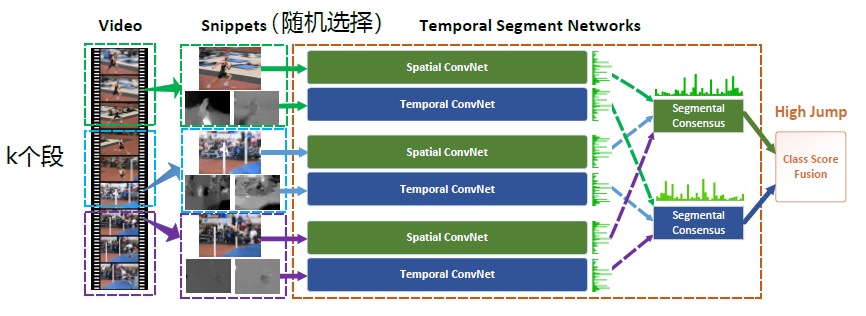
由上图所示,一个输入视频被分为 KK 段(segment),一个片段(snippet)从它对应的段中随机采样得到。不同片段的类别得分采用段共识函数(The segmental consensus function)进行融合来产生段共识(segmental consensus),这是一个视频级的预测。然后对所有模式的预测融合产生最终的预测结果。
# ResNet 101、 BN-Inception模型+注意力 比较
两种模型在训练完整图像时表现差不多,但结合注意力后,R-101有4%的改进,I-V2不改善效果。
说明两模型的主要区别:Inception-style models在输入图片的初始层通过max-pooling快速下采样,这样在后续层计算成本降低,训练更快,但是它导致大多数层具有非常大的感受野,因此后来的神经元可以有效地访问所有图像像素。这表明最后一层的所有空间特征可能非常相似。
而R-101,逐渐降低空间分辨率,允许最后一层特征专注于图像的不同部分,因此更多地受益于注意力集中。输入的图片size需要稍大一些,以确保the last-layer features are sufficiently distinct to benefit from attentional pooling.
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition (ECCV2016)
阅读时间:
TACNet: Transition-Aware Context Network for Spatio-Temporal Action Detection(CVPR2019)
阅读时间:2019.6.21
1.问题
之前方法的缺陷:空间-时间流方法动作识别方法将视频帧视为一组独立图像,无法利用视频的时间连续性
之前方法的缺陷:ACT虽然采用堆叠策略来利用剪辑级检测的短期时间连续性,但仍无法提取长期时间上下文信息,显著提高识别性能。
该网络克服的问题:提取长期时间背景信息,区分过渡状态,提出a common and differential mode scheme to accelerate the convergence of TACNet。
2.方法
提出转换感知上下文网络(TACNet)包括两个主要组件,即时间上下文检测器和转换感知分类器。
时间上下文检测器可以通过构建循环网络(standard SSD framework, but can encode the long-term context information by embedding several multi-scale Bi-directional Conv-LSTM units)来提取具有恒定时间复杂度的长期上下文信息。
转变感知分类器可以通过同时分类动作和过渡状态来进一步区分过渡状态。因此,所提出的TACNet可以显着改善时空行为检测的性能
将Bi-ConvLSTM单元嵌入到SSD框架中以设计循环检测器。作为一种LSTM,ConvLSTM可以编码长期信息,更适合处理视频等时空数据。
3.收获
# SSD、ACT、Con-LSTM
-ACT detector:分析视频序列,检测某些动作发生的时空位置(起止时间和每一帧视频中的发生位置),即spatio-temporal action localization。
步骤:1.将每一帧的视频按照时序输入到SSD网络; 2.将SSD网络中的各层特征图按照STACK排列,简单说就是,将各层特征按照,同层特征横向排列,不同层特征纵向排列。这样就将各层的特征按照时序组织起来了。

- SSD网络:目标检测
3D data
Describing Local Reference Frames for 3-D Motion Trajectory Recognition(IEEE access 2018)
阅读时间:2019.6.17
1. 问题
运动轨迹的原始数据或绘制简单的几何量不能表征3D点的方向变化。
高阶导数是3D点轨迹的一种完整描述符,可表示点的位置和方向变化,但对轨迹中的噪声敏感。
2. 方法
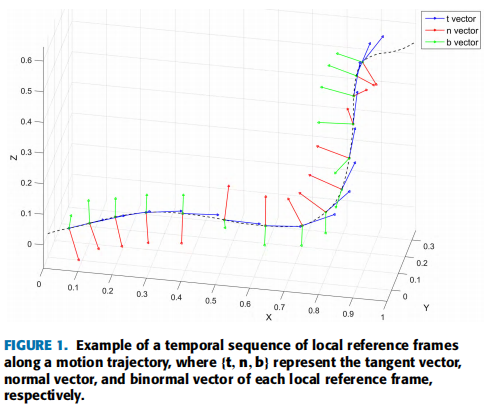
使用弗莱纳(Frenet–Serret)公式(切向量t; 法向量n; 正常向量b)表示3D运动轨迹
欧拉旋转定理 + 平方根速度矢量 作为 descriptor
Fisher Vector作为输入:Fisher kernels对输入向量进行了编码,以一个新的梯度向量来表示原输入向量,这个新的梯度向量就是Fisher Vector。这样编码的好处在于可以将任意长度的输入向量转换成定长向量
3. 收获
-使用向量表示3D运动轨迹,G(t)={x(t),y(t),z(t),t是时间
轨迹用弗莱纳(Frenet–Serret)公式(切向量t; 法向量n; 正常向量b)表示
- 识别效果不如最好的实验,理由:1、我们只使用了唇部的数据,而其他的数据使用了整个脸部的数据;2、使用的160个唇部深度数据比RGB整个脸部或唇部图片小很多,训练速度快,占用内存少。
- 提出了一种运动轨迹描述方法,在沿运动轨迹的每个点都用descriptor表示,描述了运动的方向
- 可以把descriptor 和原始数据拼接后放入神经网络;或分别用底层神经网络提取特征后在融合训练。
** # 其他的3D数据描述方式 **
微分不变量、积分不变量、SRVF、多尺度SSM、3D形状背景、LRFb
16年Convolutional Two-Stream Network Fusion for Video Action Recognition
此论文有公开源代码,用的是MATLAB。
17年Hidden Two-Stream Convolutional Networks for Action Recognition
此论文有公开源代码,用的是Caffe。
可以尝试
C3D、 P3D、 attention
弗莱纳(Frenet–Serret)公式