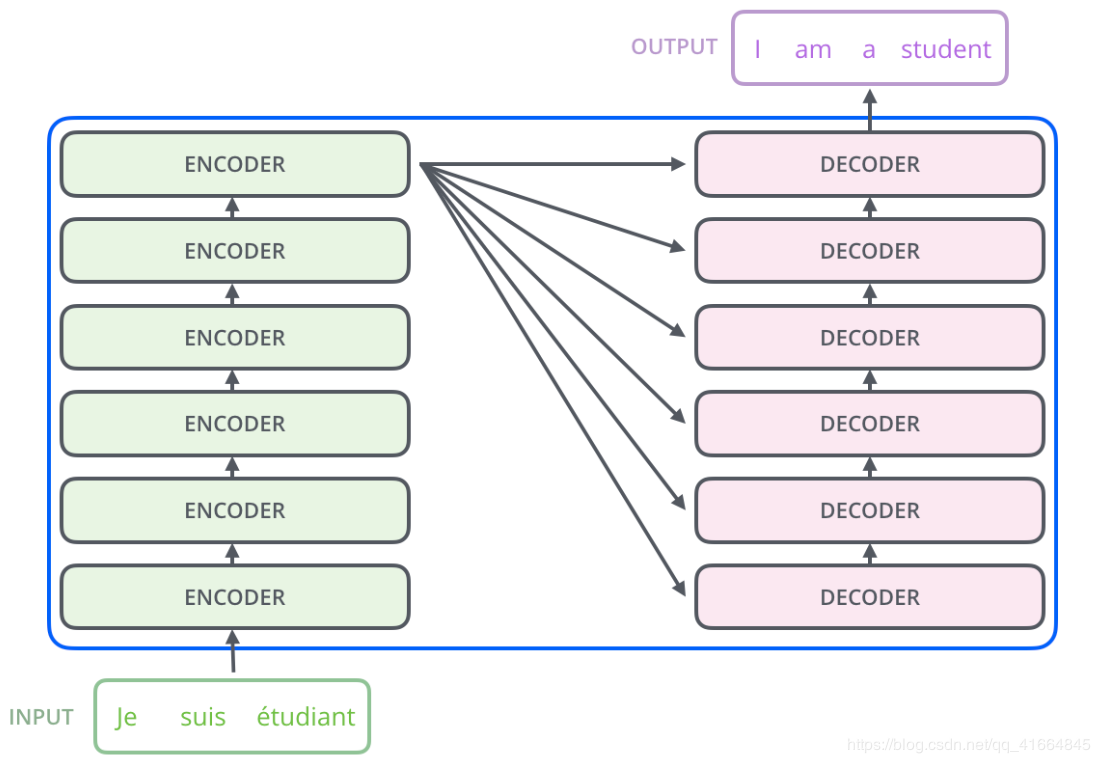
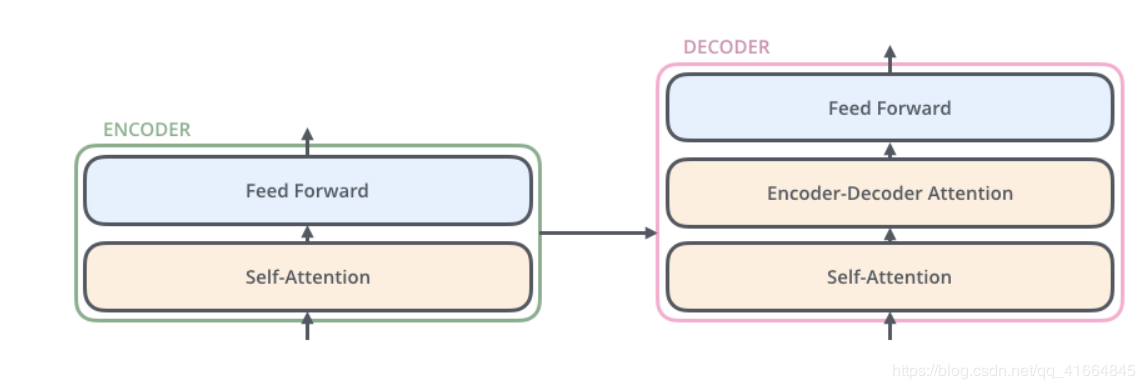
encoder & decoder
attention
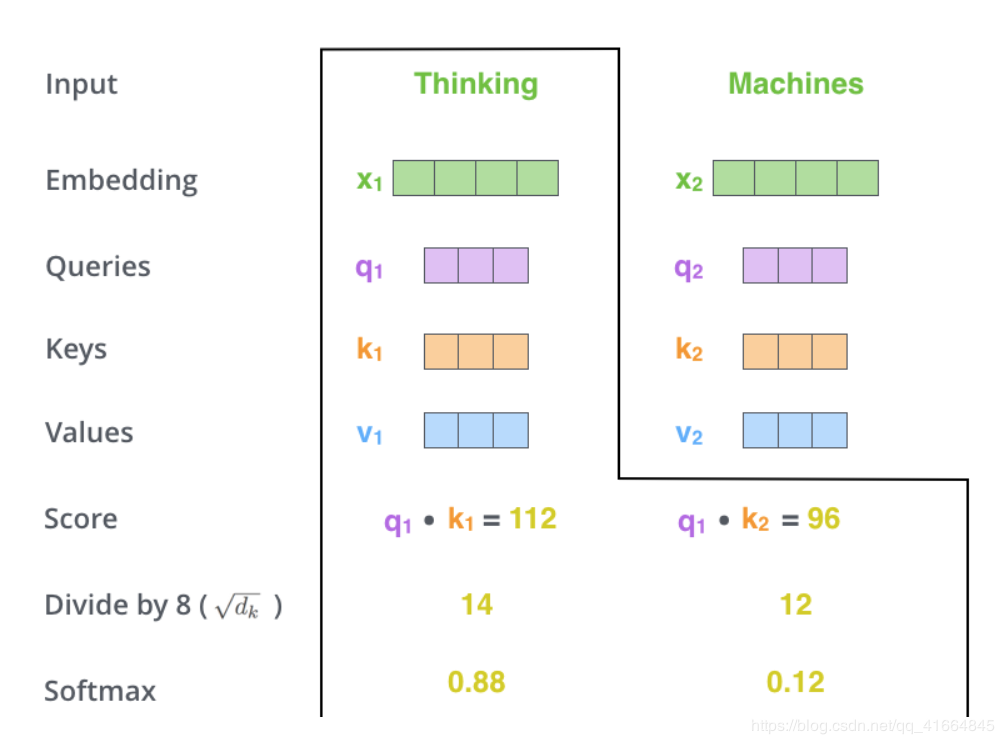
- self-attention的计算过程 实际用矩阵表示
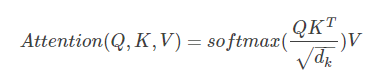
- Multi-Head Attention
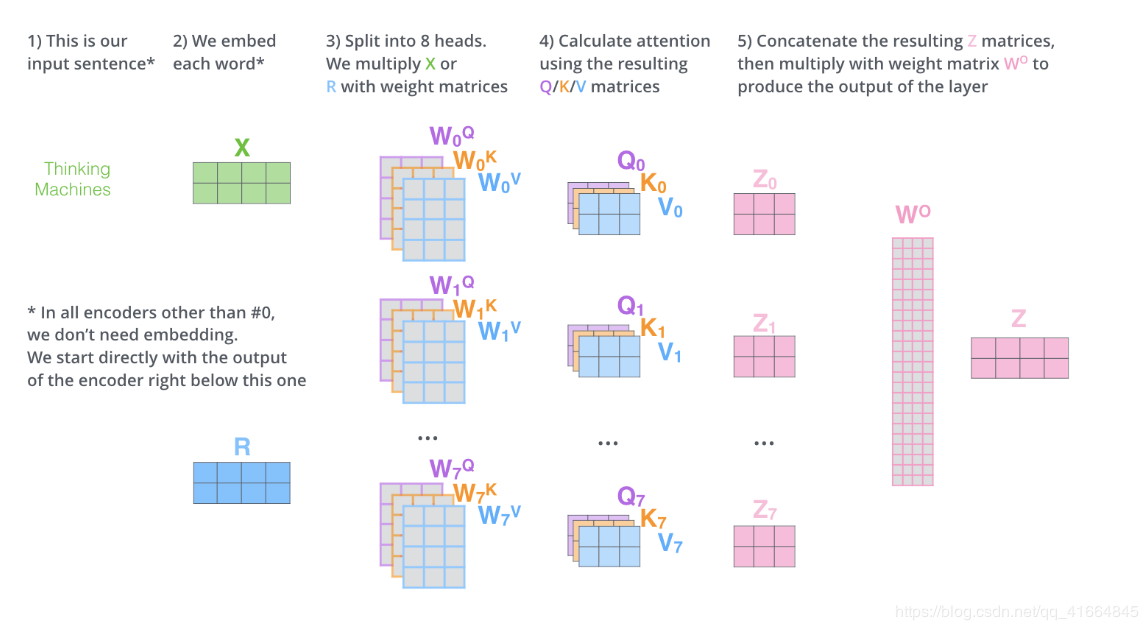
用“Multi-headed”的机制来进一步完善self attention层的性能,在self attention中,我们有多个个Query / Key / Value权重矩阵。
Transformer使用8个attention heads,每个attention head独立维护一套Q/K/V的权值矩阵,最后得到8个不同的Z矩阵。
Multi-head attention使模型共同关注来自不同位置的不同表示子空间的信息。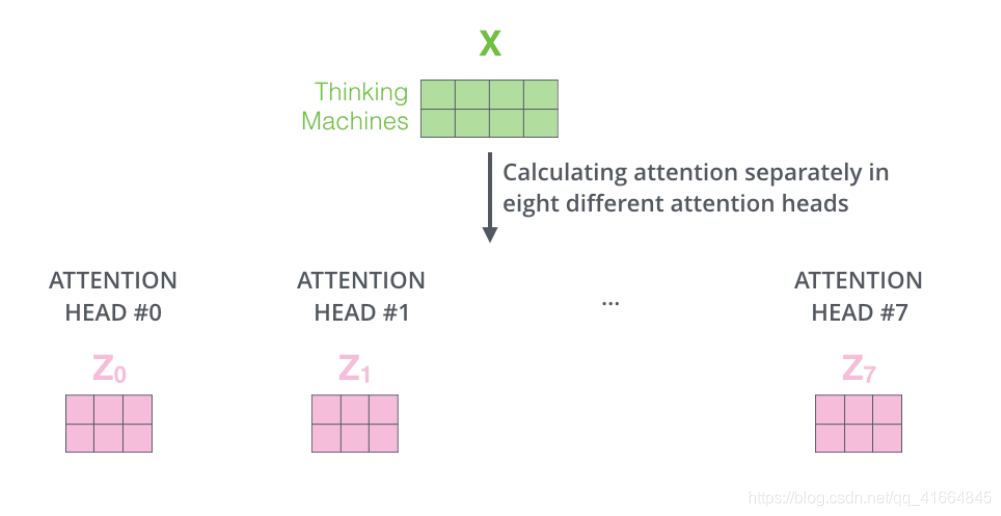
然后把所有z矩阵拼为一个矩阵,再通过线性变换用一个矩阵W相乘,得到最终的输出。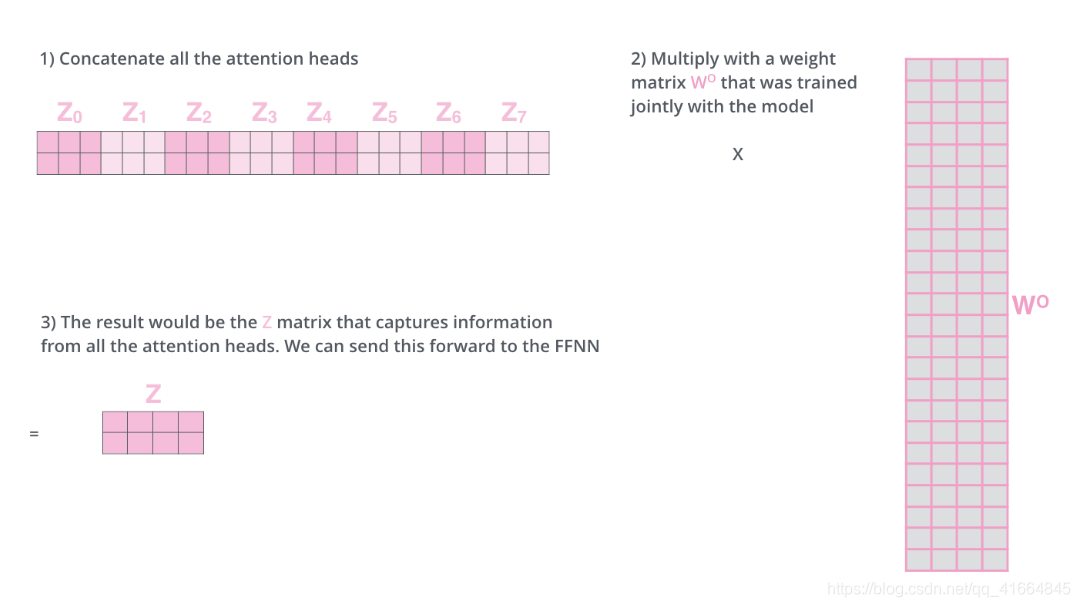
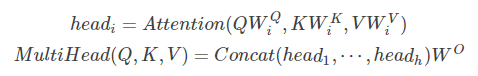
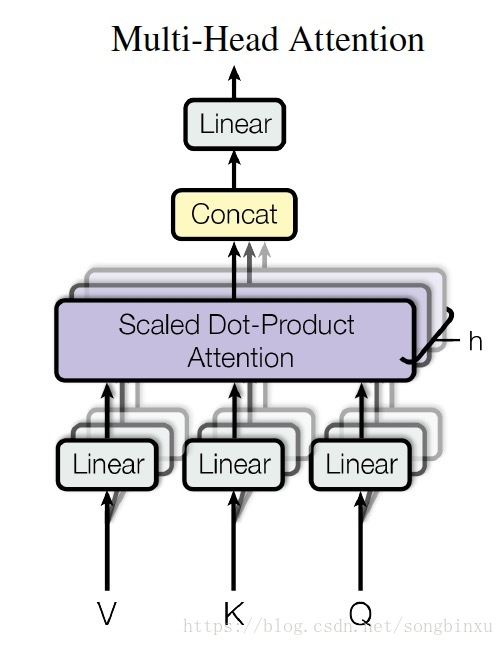
- Decoder
当序列输入时,Encoder开始工作,最后在其顶层的Encoder输出矢量组成的列表,然后我们将其转化为一组attention的集合(K,V)。(K,V)将带入每个Decoder的“encoder-decoder attention”层中去计算(这样有助于decoder捕获输入序列的位置信息)。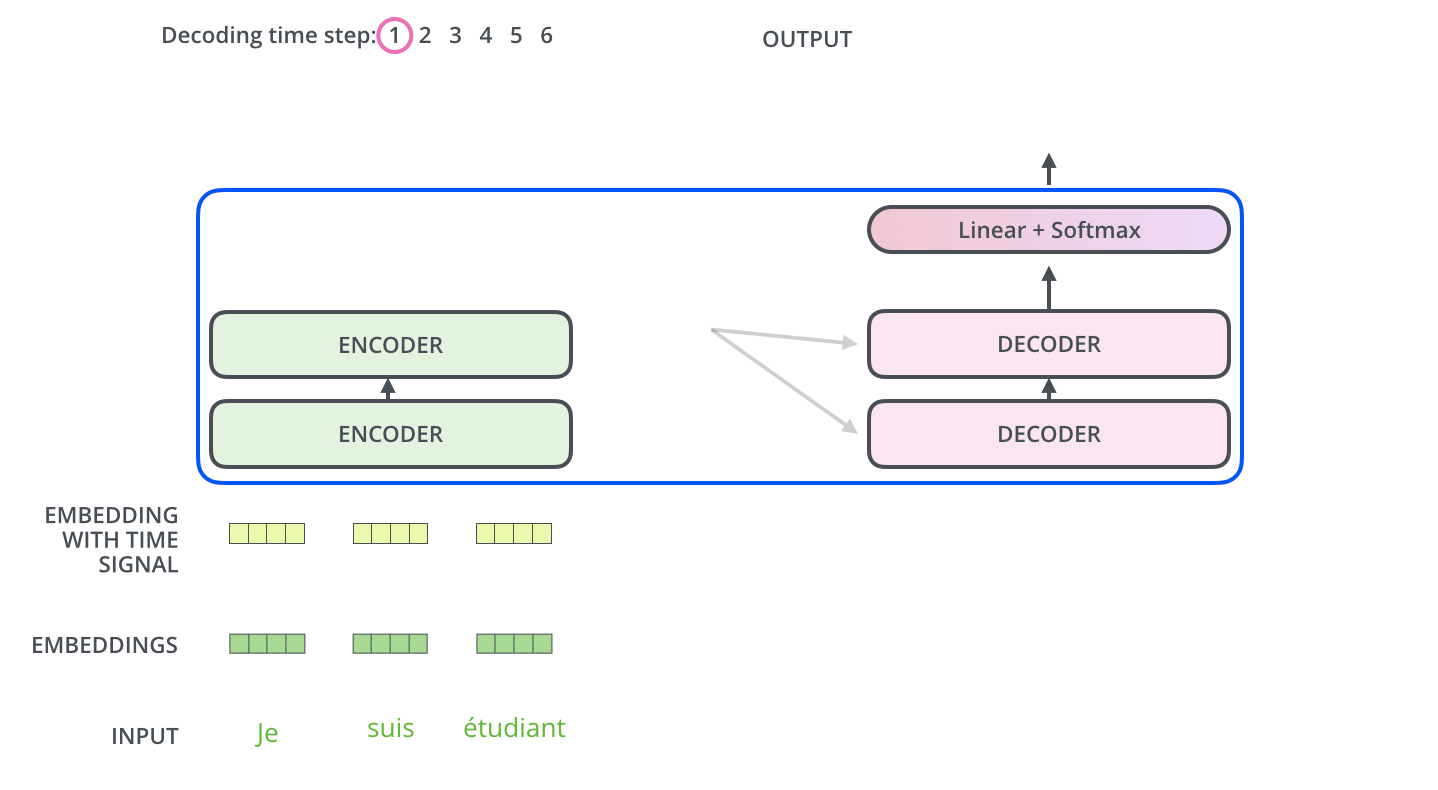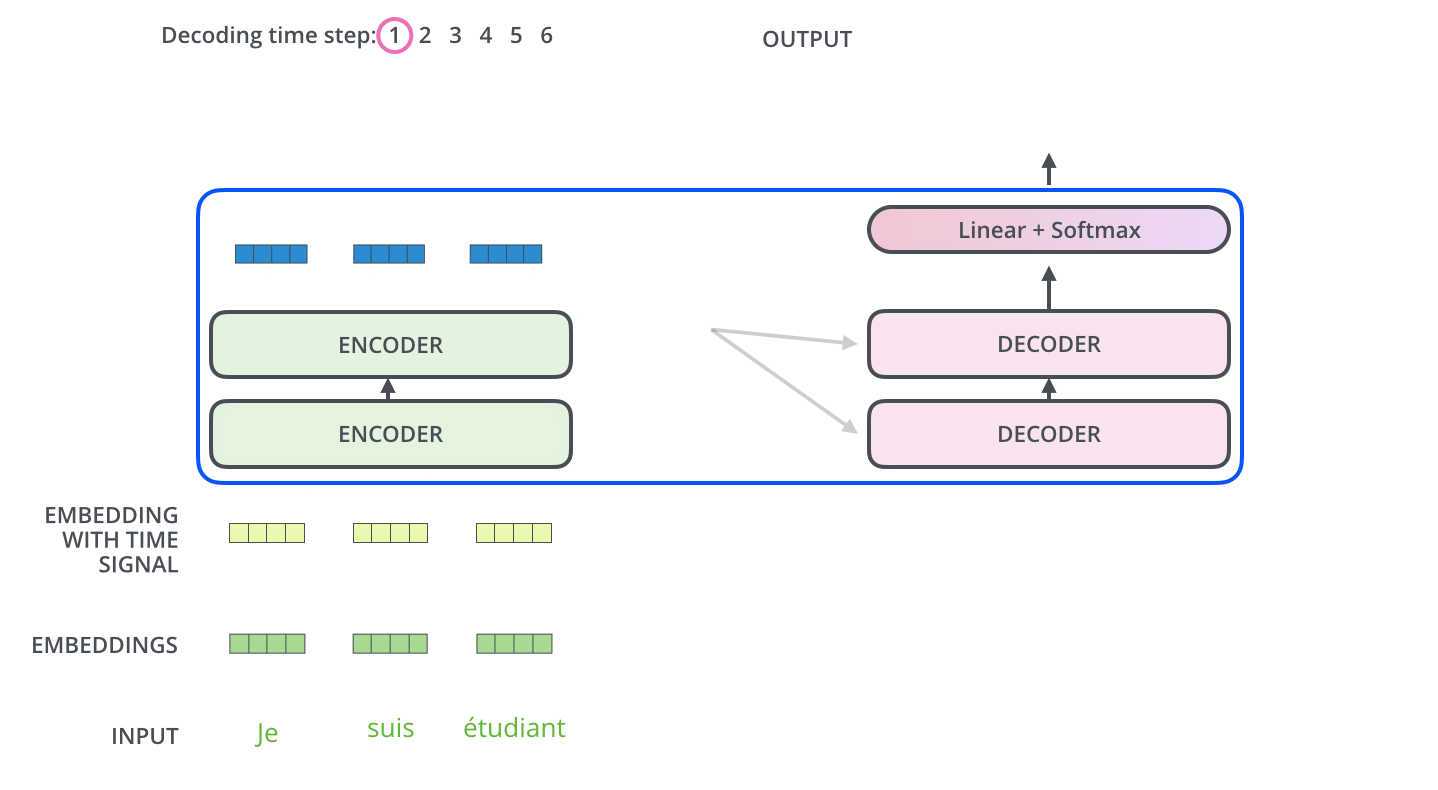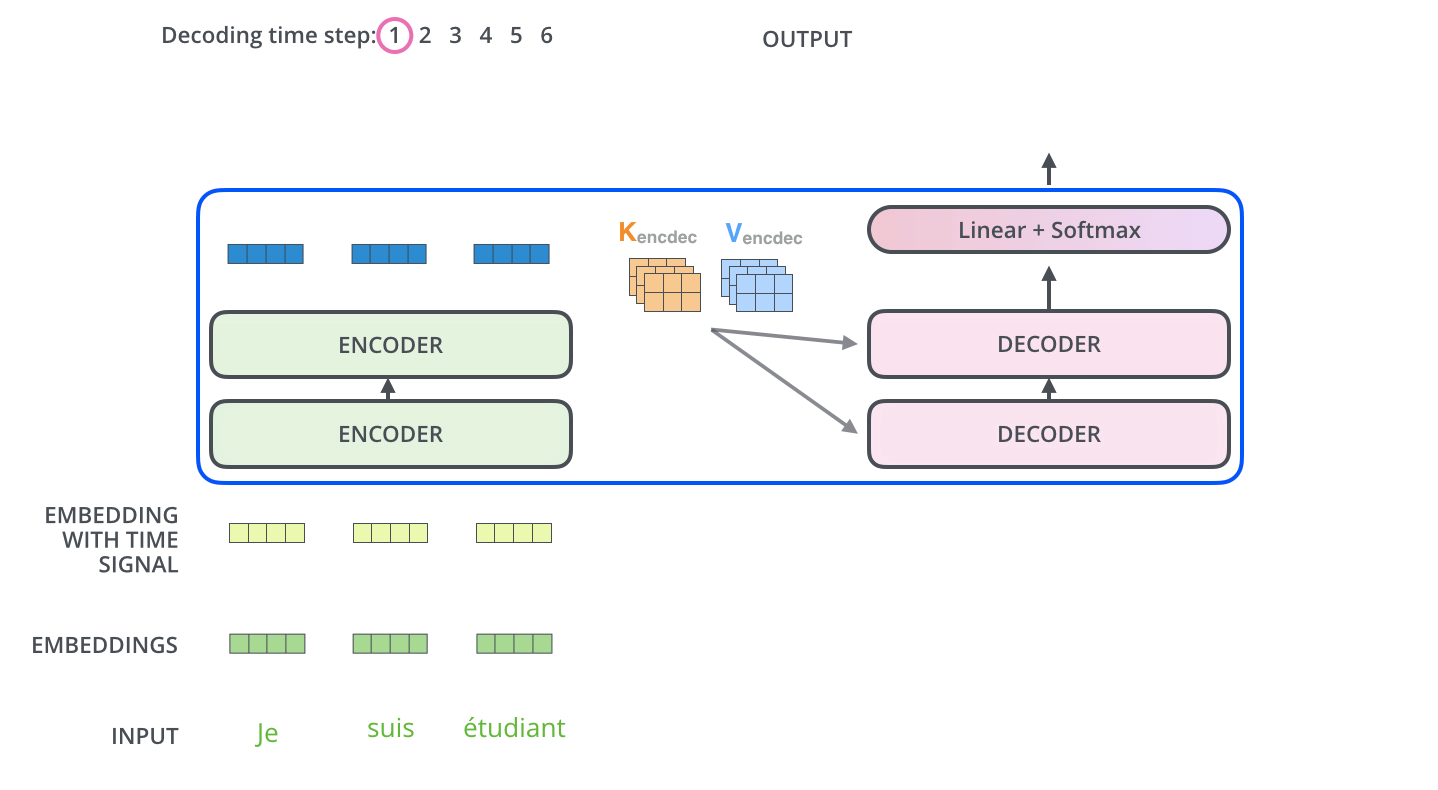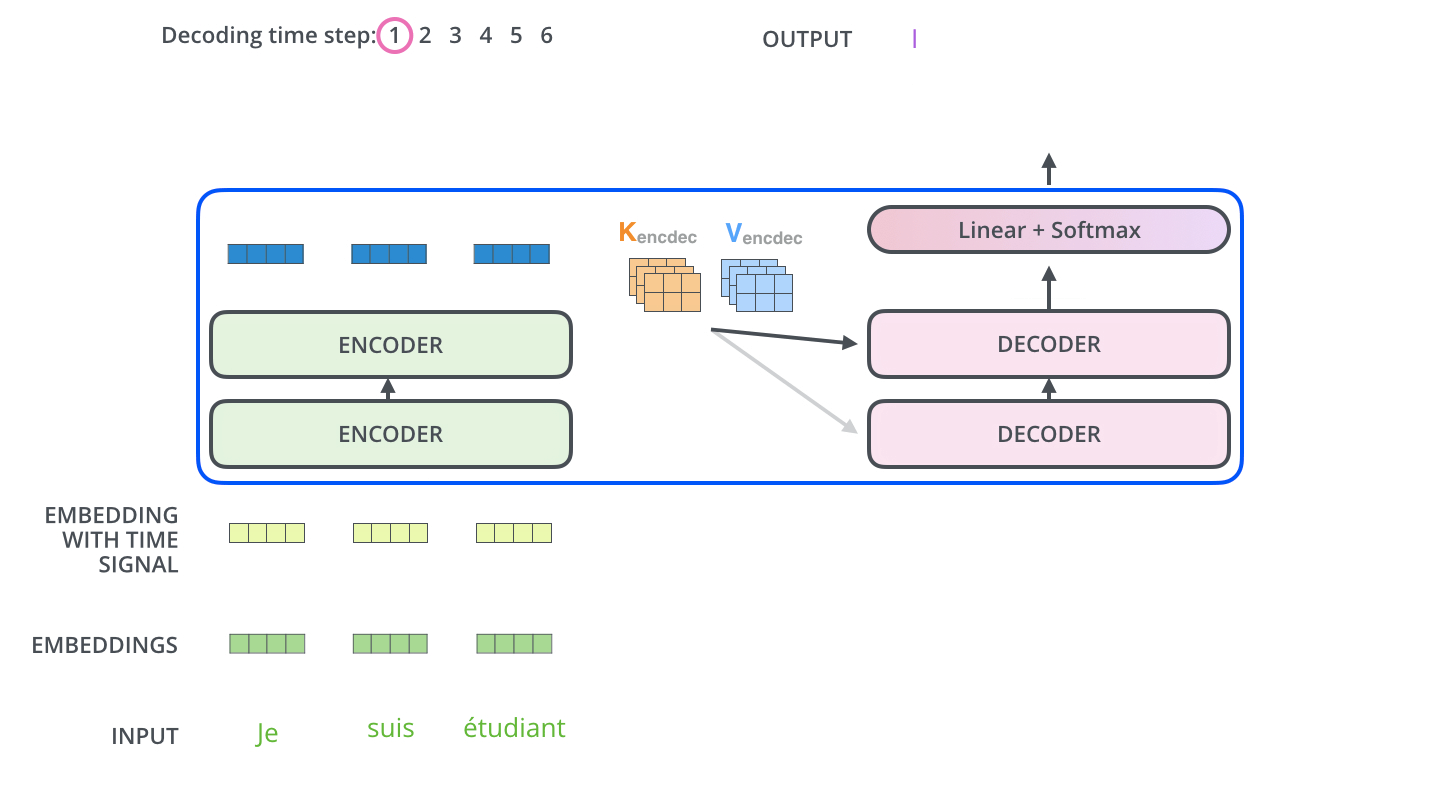
完成encoder阶段后,我们开始decoder阶段,decoder阶段中的每个步骤输出来自输出序列的元素。
我们以下图的步骤进行训练,直到输出一个特殊的符号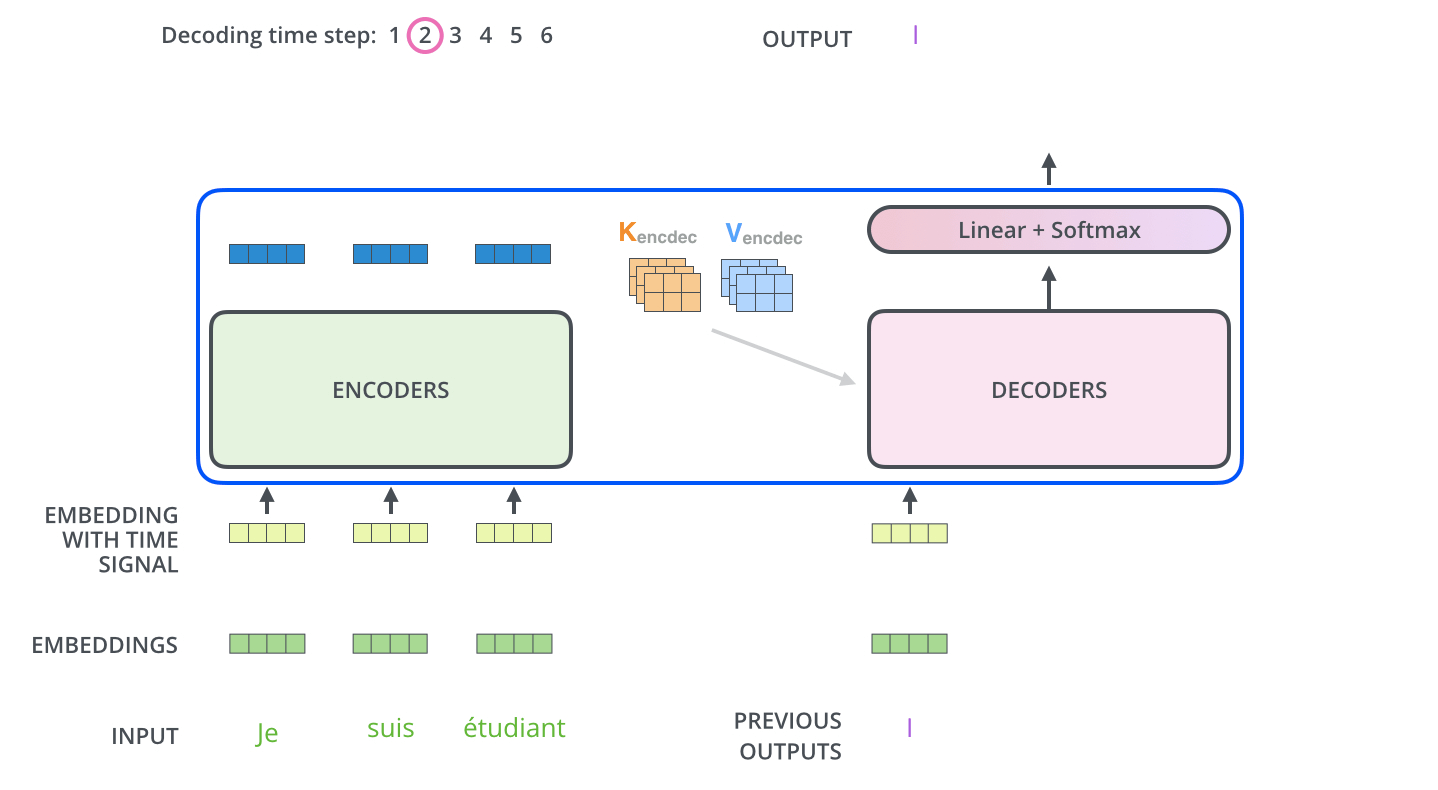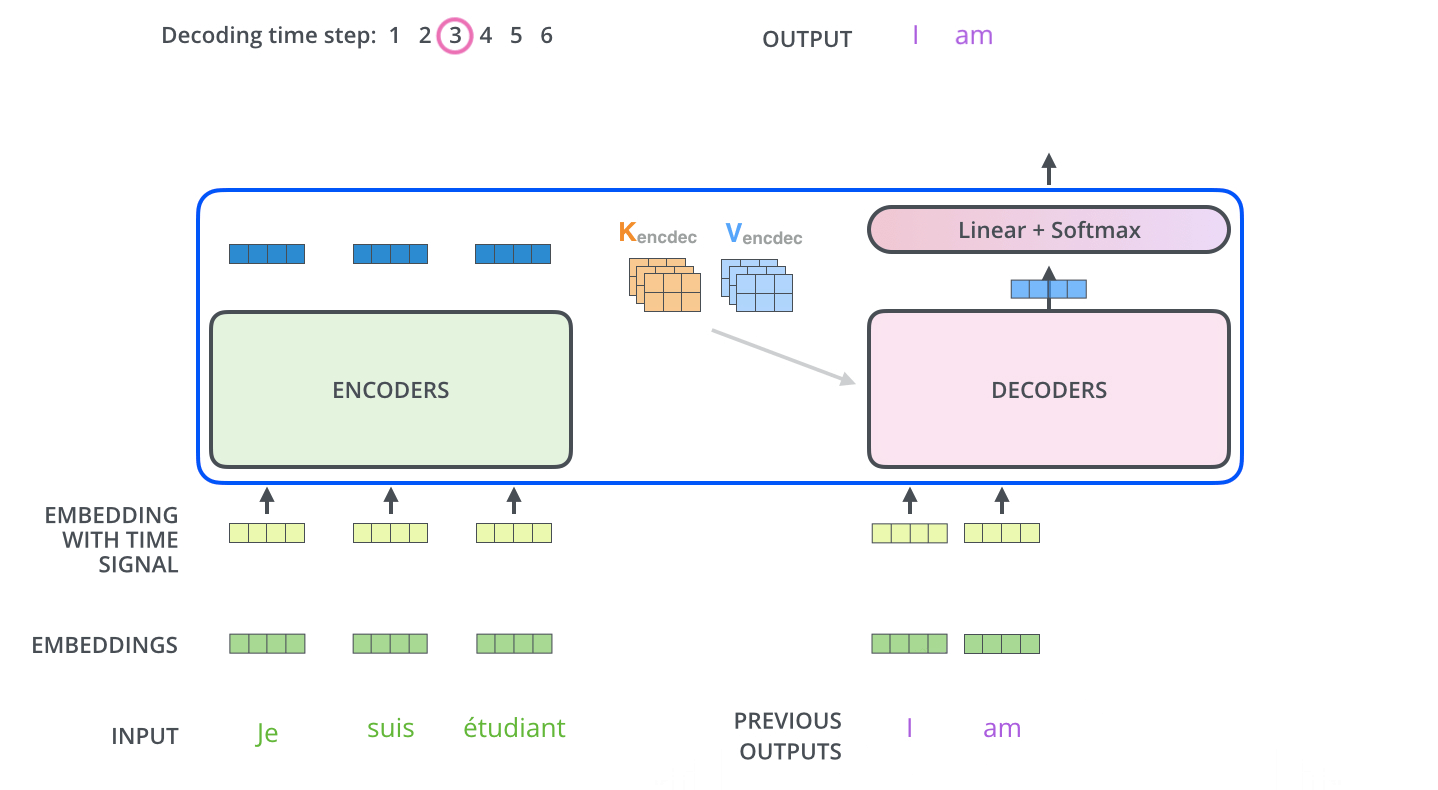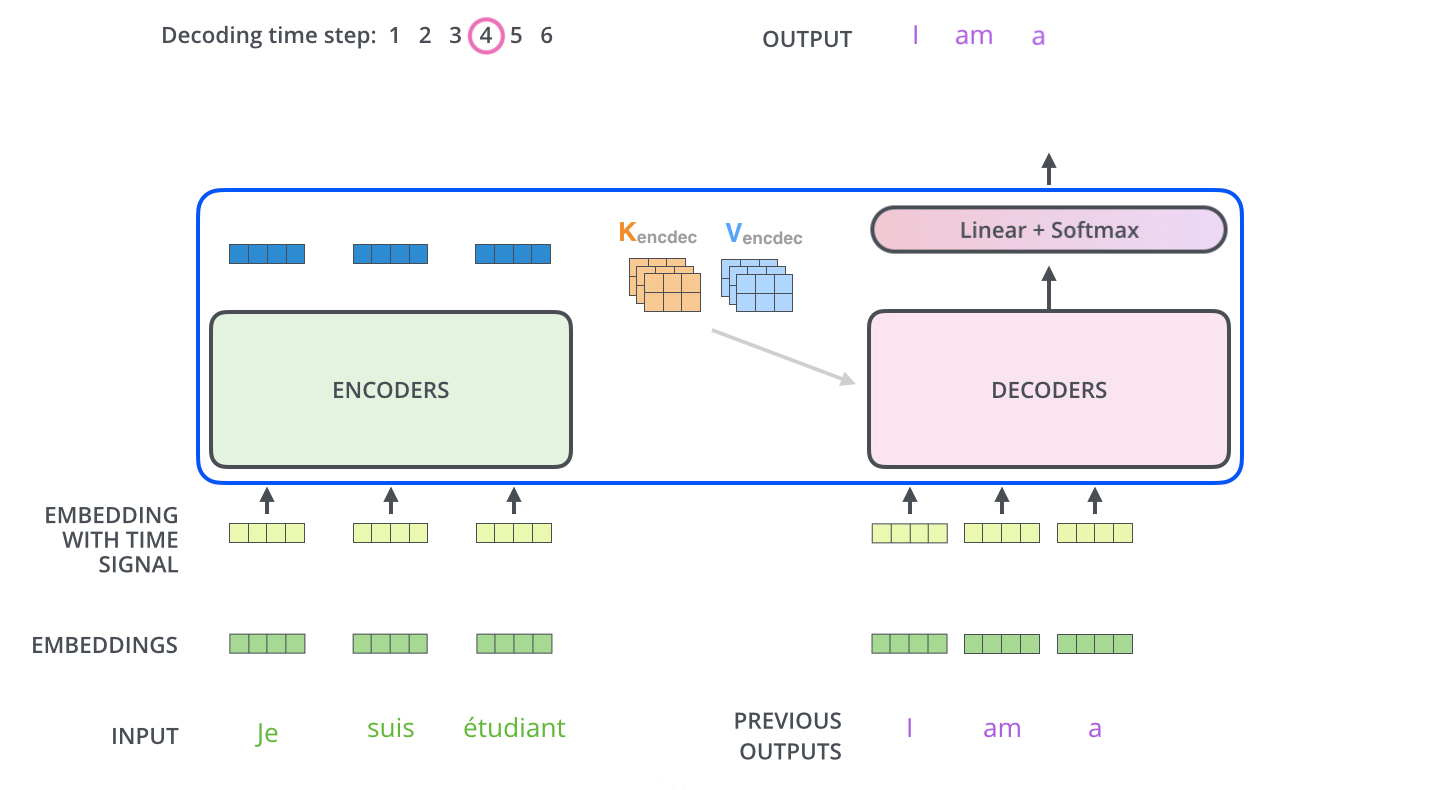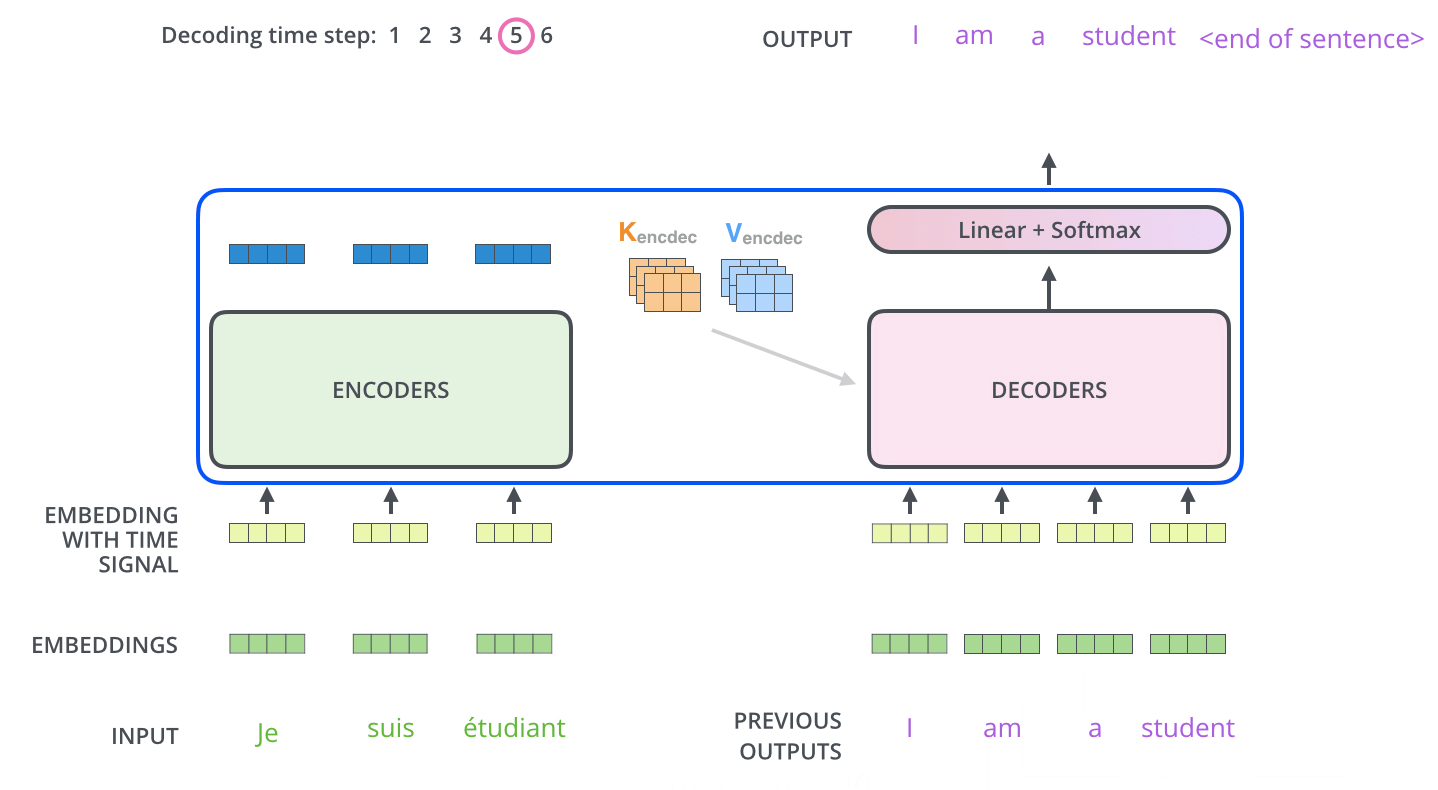
- Linear and Softmax
Decoder的输出是浮点数的向量列表,最终的线性层和softmax层把向量列表转化为单词。
全连接线性层把训练过的所有单词的投影到一个向量中。softmax将这些分数转换为概率。选取概率最高的索引,然后通过这个索引找到对应的单词作为输出。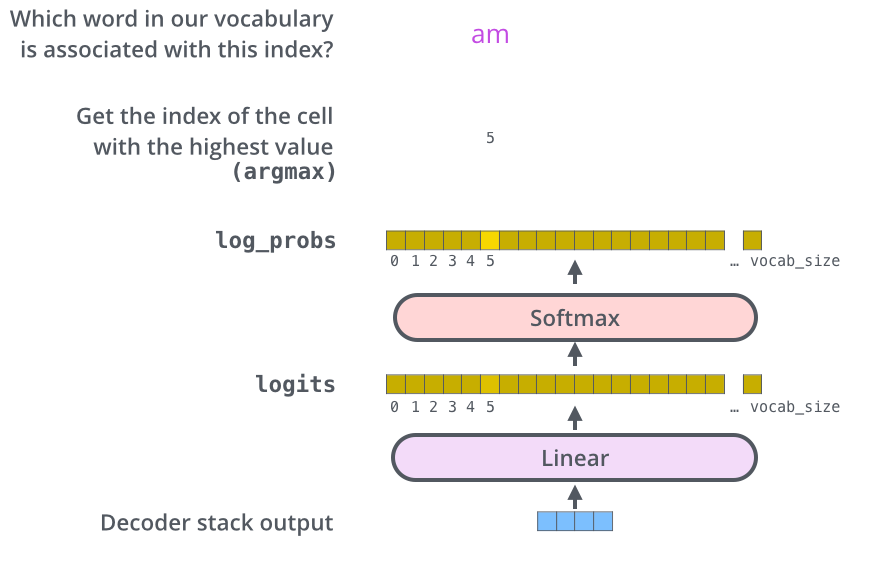
- Applications of Attention in our Model
(1)在encoder-decoder attention layer中,queriers 会参考前面的 decoder层和 encoder 输出的 keys 和 values,类似seq2seq 模型中的经典encoder-decoder 注意力机制。
(2)encoder包含self-attention层,在self-attention层中所有的key、value和query都来自前一层的encoder。这样encoder的每个位置都能去关注前一层encoder输出的所有位置。
(3)类似encoder层,decoder中也有self-attention层。
- 位置编码
由于该模型不包含递归和没有卷积,为了使模型能够利用序列的顺序,必须增加关于序列中相对或绝对位置的信息。 因此,添加“positional encodings”到the input embeddings at the bottoms of the encoder and decoder stacks中。