总结CNN、ResNet、DenseNet。
总结:
LeNet是第一个成功应用于手写字体识别的卷积神经网络 ALexNet展示了卷积神经网络的强大性能,开创了卷积神经网络空前的高潮
ZFNet通过可视化展示了卷积神经网络各层的功能和作用
VGG采用堆积的小卷积核替代采用大的卷积核,堆叠的小卷积核的卷积层等同于单个的大卷积核的卷积层,不仅能够增加决策函数的判别性还能减少参数量
GoogleNet增加了卷积神经网络的宽度,在多个不同尺寸的卷积核上进行卷积后再聚合,并使用1*1卷积降维减少参数量
ResNet解决了网络模型的退化问题,允许神经网络更深
注:关于AlexNet,GoogleNet,VGG和ResNet网络架构的demo代码见:https://github.com/skloisMary/demo-Network.git
参考博客:
AlexNet、ZFNet、VGGNet、GoogleNet和ResNet模型
https://blog.csdn.net/weixin_42111770/article/details/80719302**
GoogLeNet(从Inception v1到v4的演进)
https://my.oschina.net/u/876354/blog/1637819**
各种CNN变形
###
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如最近的GoogLenet,VGG-19,Incepetion等模型。
使用CNN作为基本构建块,为了减少顺序计算的模型有the Extended Neural GPU, ByteNet and ConvS2S,它们并行计算所有input的hidden representations和 output 的 positions。 在这些模型中,关联来自两个任意输入或输出位置的信号所需的操作数量,随距离的增长,对于ConvS2S呈线性增长,对于ByteNet呈对数增长。
###

###
###
ResNet可以解决“随着网络加深,准确率不下降”的问题
ResNet模型是CNN史上的一个里程碑事件,核心是通过建立前面层与后面层之间的“短路连接”,这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络,从而实现更高的准确度。
针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深,其中引入了全新的结构如图:
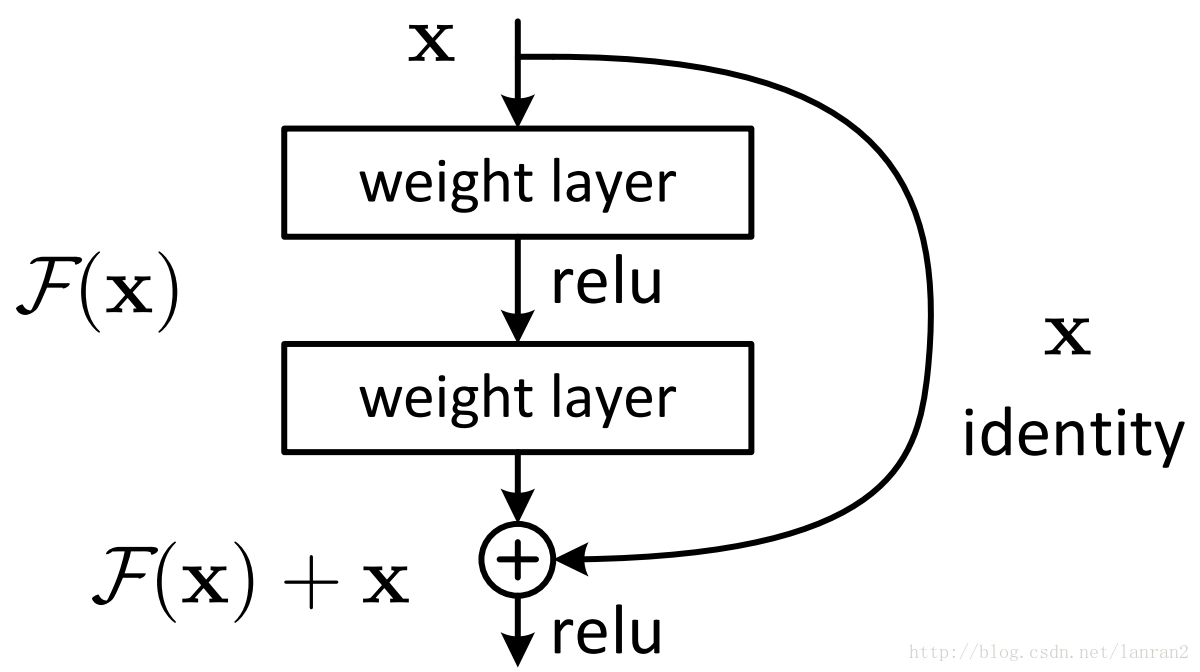
其中ResNet提出了两种mapping:
一种是identity mapping,指的就是图1中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 y=F(x)+xy=F(x)+x
identity mapping顾名思义,就是指本身,也就是公式中的xx,而residual mapping指的是“差”,也就是y−xy−x,所以残差指的就是F(x)部分。
理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式,也就是identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
真正在使用的ResNet模块并不是这么单一,文章中就提出了两种方式:
见下方博客地址
博客
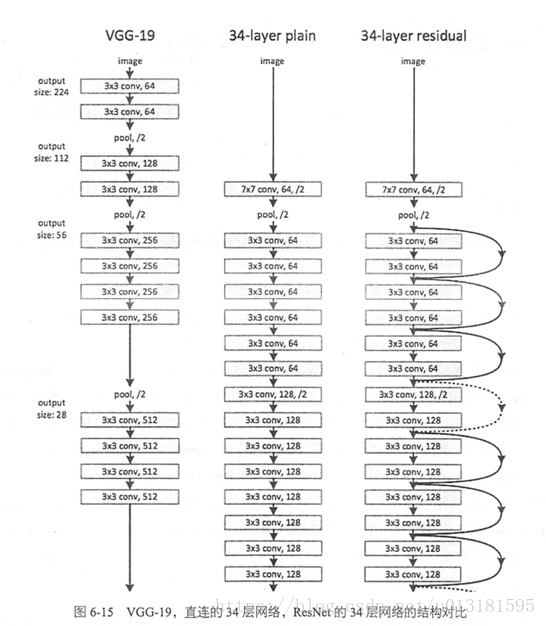
VGGNet和ResNet的对比如下图所示。ResNet最大的区别在于有很多的旁路将输入直接连接到后面的层
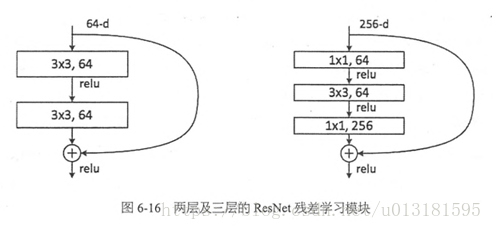
ResNet的两种残差模块
一种是以两个3*3的卷积网络串接在一起作为一个残差模块,另外一种是1*1、3*3、1*1的3个卷积网络串接在一起作为一个残差模块。他们如下图所示
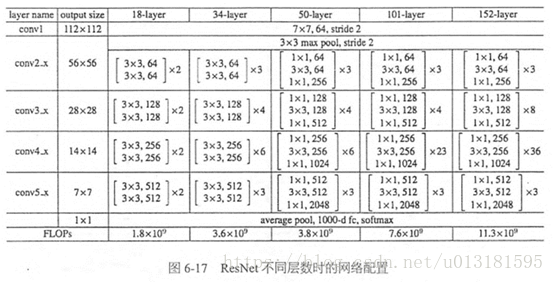
ResNet有不同的网络层数,比较常用的是50-layer,101-layer,152-layer。他们都是由上述的残差模块堆叠在一起实现的
###
DenseNet吸收了ResNet最精华的部分,并在此上做了更加创新的工作,使得网络性能进一步提升。提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。
闪光点——密集连接:缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量
DenseNet 是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。下图是 DenseNet 的一个dense block示意图,一个block里面的结构如下,与ResNet中的BottleNeck基本一致,而一个DenseNet则由多个这种block组成。
每个DenseBlock的之间层称为transition layers,由BN−>Conv(1×1)−>averagePooling(2×2)组成
DenseNet 比其他网络效率更高,其关键就在于网络每层计算量的减少以及特征的重复利用。DenseNet则是让l层的输入直接影响到之后的所有层,它的输出为:xl=Hl([X0,X1,…,xl−1]),其中[x0,x1,…,xl−1]就是将之前的feature map以通道的维度进行合并。并且由于每一层都包含之前所有层的输出信息,因此其只需要很少的特征图就够了,这也是为什么DneseNet的参数量较其他模型大大减少的原因。这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题
需要明确一点,dense connectivity 仅仅是在一个dense block里的,不同dense block 之间是没有dense connectivity的,比如下图所示。

在同层深度下获得更好的收敛率,自然是有额外代价的。其代价之一,就是其恐怖如斯的内存占用。
###
attention就是一个相似性的度量,其实就是一个当前的输入与输出的匹配度,当前的输入与目标状态越相似,那么在当前的输入的权重就会越大,说明当前的输出越依赖于当前的输入。严格来说,Attention并算不上是一种新的model,而仅仅是在以往的模型中加入attention的思想。
没有attention机制的encoder-decoder结构通常把encoder的最后一个状态作为decoder的输入(可能作为初始化,也可能作为每一时刻的输入),但是encoder的state毕竟是有限的,存储不了太多的信息,对于decoder过程,每一个步骤都和之前的输入都没有关系了,只与这个传入的state有关。attention机制的引入之后,decoder根据时刻的不同,让每一时刻的输入都有所不同。
再引用tensorflow源码attention_decoder()函数关于attention的注释:
“In this context ‘attention’ means that, during decoding, the RNN can look up information in the additional tensor attention_states, and it does this by focusing on a few entries from the tensor.”
###
###
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
THAT’S IT。其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。BN说到底就是这么个机制,方法很简单,道理很深刻。